
Modelling Your MongoDB for OLTP: Embracing the Single Collection Design
In the context of designing a database schema, a high velocity pattern refers to a data model that is optimized for handling a large volume of rapidly changing data. It is typically associated with applications that deal with real-time data processing, such as streaming analytics, IoT (Internet of Things) systems, social media platforms, and financial trading systems.
When working with high velocity data, the database schema needs to be designed in a way that allows for efficient storage, retrieval, and processing of data at a high rate. Here are a few characteristics of a high velocity pattern:
-
Denormalization: High velocity patterns often involve denormalizing the data model to reduce the number of joins and improve query performance. By duplicating data across multiple tables or embedding related data within a single table, you can minimize the need for expensive joins during real-time processing.
-
Partitioning: Partitioning involves dividing the data into smaller, manageable chunks based on certain criteria (e.g., time intervals or data ranges). This technique helps distribute the data across multiple physical storage locations or servers, enabling parallel processing and faster data access.
-
Sharding: Sharding is a technique that involves horizontally partitioning data across multiple databases or servers. Each shard contains a subset of the data, allowing for parallel processing and improved scalability. Sharding is particularly useful for handling high velocity workloads with large volumes of data.
-
Caching: To enhance query performance and reduce the load on the database, caching can be employed. Caching involves storing frequently accessed data in a high-speed cache, such as an in-memory store, to serve subsequent requests quickly.
-
Event-driven architecture: High velocity patterns often rely on event-driven architectures, where data changes or events trigger workflows or actions. By using event-based messaging systems or publish-subscribe models, you can efficiently process and react to incoming data in real-time.
It’s important to note that the design considerations for a high velocity pattern may introduce trade-offs in terms of data consistency, storage requirements, and complexity. Therefore, careful analysis of the specific requirements and characteristics of the application is necessary to determine the most suitable design approach.
OLTP
A high velocity pattern is often associated with OLTP (Online Transaction Processing) databases. OLTP databases are designed to handle high volumes of transactions and provide real-time data processing capabilities. They are typically used for operational systems where data is constantly updated, inserted, and queried in a concurrent manner.
The high velocity pattern aligns with the requirements of OLTP systems by optimizing the database schema for efficient handling of rapidly changing data. The denormalization, partitioning, sharding, and caching techniques mentioned earlier are commonly employed in OLTP environments to ensure fast response times and scalable performance.
In OLTP databases, the focus is on maintaining data integrity, supporting transactional consistency, and providing quick access to the most up-to-date data. This is in contrast to OLAP (Online Analytical Processing) databases, which are designed for complex analytics and reporting on historical data. While high velocity patterns can be applied to OLAP databases as well, they are particularly relevant in the context of OLTP systems due to the real-time, transactional nature of the data being processed.
What type of Database schema would I consider for a CRM application
A CRM (Customer Relationship Management) application typically falls into the OLTP (Online Transaction Processing) category.
Here’s why:
-
Real-time data updates: A CRM application deals with real-time customer data, including contact information, interactions, sales, and support activities. It requires immediate and frequent updates to reflect the latest customer interactions and activities. OLTP databases are designed for such transactional systems that handle rapid data updates.
-
Transactional nature: CRM applications involve a significant number of transactional operations, such as creating, updating, and deleting customer records, tracking sales orders, managing leads, and recording customer interactions. OLTP databases excel at handling these transactional workloads and ensuring data consistency and integrity.
-
Concurrent user access: CRM systems often have multiple users accessing and modifying customer data concurrently. OLTP databases are optimized for handling concurrent operations by employing locking mechanisms, transaction isolation levels, and ensuring ACID (Atomicity, Consistency, Isolation, Durability) properties to maintain data integrity in a multi-user environment.
-
Operational decision-making: CRM applications primarily serve the operational needs of a business, focusing on day-to-day customer interactions, sales activities, and support operations. The data stored in an OLTP database supports operational decision-making, such as managing customer relationships, generating reports on sales performance, tracking customer service metrics, and facilitating real-time interactions with customers.
While CRM applications may also involve reporting and analytics features to provide insights into customer data, the core functionality revolves around managing and processing transactional data in real-time. OLAP databases, on the other hand, are specifically designed for complex analytics and reporting on historical data, catering to strategic and analytical decision-making.
The ERD for a typical CRM is
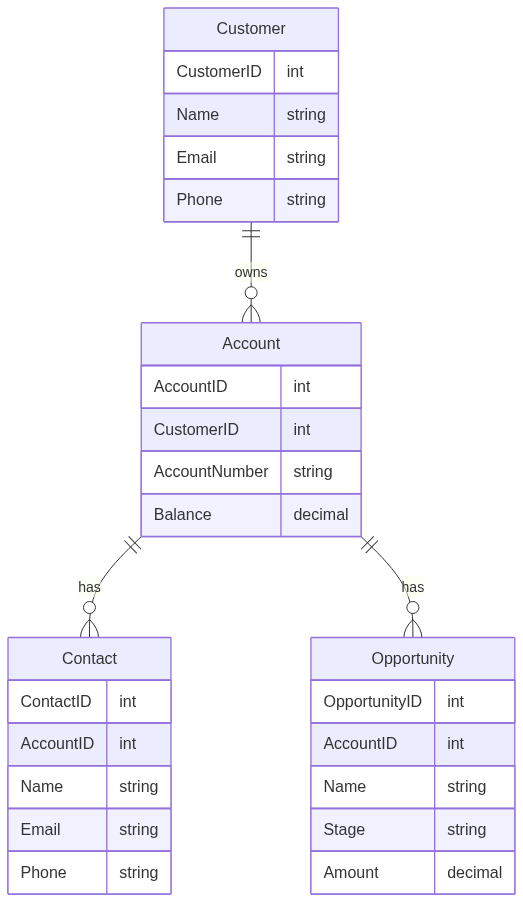
and the corresponding RDBMS schema would be:
-- Create tables
CREATE TABLE Customer (
CustomerID SERIAL PRIMARY KEY,
Name VARCHAR(255) NOT NULL,
Email VARCHAR(255),
Phone VARCHAR(20)
);
CREATE TABLE Account (
AccountID SERIAL PRIMARY KEY,
CustomerID INT NOT NULL,
AccountNumber VARCHAR(50),
Balance DECIMAL(10,2),
FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID)
);
CREATE TABLE Contact (
ContactID SERIAL PRIMARY KEY,
AccountID INT NOT NULL,
Name VARCHAR(255) NOT NULL,
Email VARCHAR(255),
Phone VARCHAR(20),
FOREIGN KEY (AccountID) REFERENCES Account(AccountID)
);
CREATE TABLE Opportunity (
OpportunityID SERIAL PRIMARY KEY,
AccountID INT NOT NULL,
Name VARCHAR(255) NOT NULL,
Stage VARCHAR(50),
Amount DECIMAL(10,2),
FOREIGN KEY (AccountID) REFERENCES Account(AccountID)
);
let’s insert some dummy data
-- Insert dummy data into Customer table
INSERT INTO Customer (Name, Email, Phone)
VALUES ('John Doe', 'john.doe@example.com', '1234567890'),
('Jane Smith', 'jane.smith@example.com', '9876543210'),
('David Johnson', 'david.johnson@example.com', '5555555555'),
('Sarah Wilson', 'sarah.wilson@example.com', '6666666666');
-- Insert dummy data into Account table
INSERT INTO Account (CustomerID, AccountNumber, Balance)
VALUES (1, 'A001', 1000.00),
(2, 'A002', 2500.00),
(3, 'A003', 500.00),
(4, 'A004', 2000.00);
-- Insert dummy data into Contact table
INSERT INTO Contact (AccountID, Name, Email, Phone)
VALUES (1, 'John Contact', 'john.contact@example.com', '1111111111'),
(2, 'Jane Contact', 'jane.contact@example.com', '2222222222'),
(3, 'David Contact', 'david.contact@example.com', '3333333333'),
(4, 'Sarah Contact', 'sarah.contact@example.com', '4444444444');
-- Insert dummy data into Opportunity table
INSERT INTO Opportunity (AccountID, Name, Stage, Amount)
VALUES (1, 'Opportunity 1', 'Prospect', 500.00),
(2, 'Opportunity 2', 'Closed Won', 1000.00),
(3, 'Opportunity 3', 'Prospect', 250.00),
(4, 'Opportunity 4', 'Closed Lost', 1500.00);
To fetch data that spans across multiple entities we have no choice but to use joins, example if we’s like to show all opportunities for a specific customer we’d have to run the following SQL command
SELECT * FROM Customer cust
INNER JOIN Account acc on acc.CustomerID = cust.CustomerID
INNER JOIN Opportunity opp on opp.AccountID = acc.AccountID
where cust.name = "John Doe"In the world of modern applications, where data volumes are growing exponentially and real-time responsiveness is a necessity, designing your database for optimal performance is crucial. MongoDB, a popular NoSQL database, offers great flexibility for data modeling. One approach gaining traction is the use of a single collection design for Online Transaction Processing (OLTP) workloads. In this blog, we’ll explore the concept of a single collection design and discuss its benefits, considerations, and best practices.
Understanding the Single Collection Design
Traditionally, in relational databases, we normalize data into multiple tables to eliminate redundancy and ensure data consistency. However, in MongoDB, denormalizing data is encouraged to optimize query performance. The single collection design takes this denormalization concept to the extreme by storing all related data within a single collection.
Benefits of the Single Collection Design
-
Improved Read and Write Performance: By storing related data together, the single collection design eliminates the need for expensive joins, reducing query complexity and improving read performance. Additionally, write operations become faster since all data modifications occur in a single collection.
-
Simplified Data Access: With a single collection, fetching related data becomes a breeze. You can retrieve all required information with a single query, reducing network latency and improving overall response times.
-
Flexible Schema Evolution: MongoDB’s schema-less nature allows for easy schema evolution. With a single collection design, accommodating changes becomes seamless, as there are no dependencies across multiple tables to update.
Considerations and Best Practices
-
Document Size Limit: MongoDB has a document size limit of 16MB. When adopting the single collection design, carefully consider the maximum document size to ensure your data fits within these limits. If your data exceeds the limit, you may need to consider alternative strategies like sharding or using GridFS for large binary data.
-
Data Relationships: While denormalizing data is encouraged, it’s important to evaluate your application’s data access patterns and determine the optimal level of denormalization. Strike a balance between reducing joins and avoiding data duplication. Identify the relationships between entities and include related data within the same document to maximize performance.
-
Indexing Strategy: Efficient indexing is essential for performance in MongoDB. Analyze your queries to identify the most frequently accessed fields and create indexes accordingly. Design compound indexes that cover multiple fields commonly used together. However, be cautious of the trade-off between read performance and increased storage requirements.
-
Data Consistency: In OLTP scenarios, maintaining data consistency is critical. With a single collection design, you must ensure atomicity and consistency during write operations. Utilize MongoDB’s atomic operations, such as transactions or multi-document ACID guarantees, to handle complex write scenarios.
Conclusion
MongoDB’s single collection design offers a powerful approach to modeling your database for OLTP workloads. By denormalizing related data into a single collection, you can achieve improved performance, simplified data access, and flexible schema evolution. However, it’s crucial to carefully consider document size limits, data relationships, indexing strategies, and data consistency to ensure optimal performance and data integrity. With proper planning and implementation, embracing the single collection design can unlock the full potential of MongoDB for your OLTP applications.